

The Intelligence Tax Explained
Imagine hiring a team of Nobel Prize Physicists to check your spelling. For years, this is how the Artificial Intelligence (AI) industry operated. The rule of the Silicon Valley was absolute: “Scale is all you Need”. To get smarter and smarter models, you needed bigger clusters, more electricity, and billions of dollars. Every time you asked a chatbot like ChatGPT or Gemini a simple question, it had to fire up its entire, massive brain, activating billions of parameters that weren’t even needed for the task. This is what we call the “Intelligent Tax”. Experts believed this “Intelligence Tax” was unavoidable. They said the laws of finance dictated that intelligence would always remain a luxury, controlled by three or four massive corporations.
But while the giants were fighting a war of resources, a small, quiet team of quantitative researchers in Hangzhou was fighting a war of mathematics. They didn’t have the infinite budget of Microsoft or the compute power of Google. Operating under severe compute constraints, they couldn’t afford to be wasteful. So, instead of trying to build a bigger engine, they asked a dangerous question to themselves: What if the engine design itself is wrong?
They worked in silence to shatter the monolithic architecture of the Transformer into thousands of tiny pieces, aiming to prove that a small, specialized swarm could outwit a giant. When they finally released their work, they didn’t just join the race, instead they crashed the market price of intelligence by 95% overnight. This is the story of DeepSeek.
The “Geek” from Zhejiang
To understand DeepSeek, you have to understand that it wasn’t born in a tech lab, it was born on a trading desk.

(Source: https://www.thetimes.com/uk/technology-uk/article/liang-wenfeng-deepseek-ai-cpp-zr65vhkl9)
Liang Wenfeng was a computer science graduate from Zhejiang University, he was described by peers as a “hardcore coder” who cared more about algorithms than business suits. In 2016, he co-founded High-Flyer, a quantitative hedge fund. By 2023, High-Flyer was managing billions in assets. Liang could have retired on a yacht. Instead, he made a crazy bet. He looked at the rise of GPT-4 and realized that China was falling dangerously behind.
The global supply of high-end AI chips (GPUs) was drying up. Western giants like Microsoft and Meta were buying every chip they could find, building massive intelligent supercomputers to brute force their way to smarter AI. Liang treated this constraint as a design challenge. He gathered a small team of researchers in Hangzhou with a singular mission: Build GPT-4 level intelligence, but do it with a fraction of the computing power.
Imagine a stock trader versus a professor. A professor might have years to write a perfect paper, but a trader has seconds to make a quick and accurate decision before they lose money. In the world of algorithmic trading, efficiency is everything. You don’t waste time as well as the compute power.
Liang didn’t have that luxury. Facing severe supply constraints, they physically could not win a battle of size. Imagine building a computer without having its parts. Most companies would have given up. Liang’s team saw it as a challenge. They realized that if they couldn’t beat the giants on power, they had to beat them on intelligence. They decided to stop trying to build a larger engine, and instead focused on building a more efficient one. This inability to spend more money became their ultimate weapon which forced them to rewrite the rules of how AI thinks which eventually led them to great technical breakthroughs.
Shattering the Monolith
While the rest of the industry was obsessed with making models bigger, DeepSeek focused on making models smarter. To understand their breakthrough, we first need to understand the problem with traditional models. In a standard model like early GPT-4 (1.8 trillion parameters), if you ask a question, every single parameter in the model’s brain fires up. It’s like lighting up an entire building just to find a pen in one office. It works, but it’s incredibly wasteful.
DeepSeek introduced two specific engineering breakthroughs that changed this logic.
1. DeepSeekMoE:
The industry was already moving toward a technique called Mixture-of-Experts (MoE). This splits the model into different “experts” (e.g., a Coding Expert, a Math Expert, a History Expert). When you ask a question, the model routes you to the right expert.
The Competitor’s Way (Standard MoE): Most models used a few massive experts. Imagine a hospital with only 8 doctors. If you have a headache, you see the “General Brain Doctor”. It’s efficient, but the doctors have to know too much general stuff.
The DeepSeek Way (Fine-Grained MoE): DeepSeek crumbled these experts into tiny, hyper-specialized pieces (64+ routed experts). Instead of a “General Brain Doctor”, they have a specific expert for ”Migraines” or one for “Tension Headaches”.
Apart from that, they added a “Shared Expert”, a dedicated block of neurons that stays active for every query. This expert handles the basics like grammar and sentence structure so the tiny specialists don’t have to relearn it. This isolation of knowledge allowed DeepSeek to activate far fewer parameters per token than Llama 3 or GPT-4, while achieving the same intelligence.
2. Multi-Head Latent Attention (MLA):
The second barrier to cheap AI is memory. As you have a long conversation with a chatbot like ChatGPT or Gemini, the “context” (history) grows. This is stored in something called the Key-Value Cache (KV Cache). For long documents, this cache gets so big it forces companies to buy expensive NVIDIA H100 GPUs just to hold the memory.
DeepSeek solved this with MLA. Think of the KV Cache like a raw, uncompressed 4K video file. It’s heavy and slow to move around. MLA acts like a ZIP file compressor. It compresses the memory into a “latent vector” (a smaller mathematical representation) before storing it.
The Result: DeepSeek models can read massive documents (128k+ tokens) using a fraction of the memory required by competitors. This didn’t just make the model faster, it made it significantly cheaper to run.
The $600 Billion Shockwave
When DeepSeek released their V2 model, they didn’t just climb the leaderboards, they completely broke the economic model of the AI industry. For years, the “Big Three” providers held a monopoly on pricing where high-level intelligence was a luxury product. But in mid-2024, DeepSeek dropped a bomb that shook the entire AI Industry.
1. The 95% Price Reduction
Because their architecture was so mathematically efficient, DeepSeek could afford to price at a fraction of their competitors. While competitors were charging around $10-30 per million tokens, DeepSeek entered the market at roughly $0.14. Giants were forced to slash their prices or risk losing the entire developer market.
But the real shock was to the hardware market. For years, Wall Street valued Nvidia based on the assumption that AI companies would need infinitely more chips every year. DeepSeek proved that you could get GPT-4 level intelligence using far fewer chips. Overnight, the market realized that the demand for GPUs might actually have a ceiling. This realization is what sent chip stocks tumbling.
2. The New King of Code
While they were generally strong in chat, DeepSeek found its place in Programming. Their coder models became a standard for open-source coding. By late 2024, millions of developers were using DeepSeek-powered extensions in their code editors (like VS Code), realizing that this free model was often better than the expensive models they had been paying for.
3. Validating Open Source
Perhaps the most significant impact was philosophical. Before DeepSeek, the narrative was that “Closed Source is safer and smarter”. DeepSeek destroyed this myth. By sharing their model publicly, they made it possible for researchers, students, and startups to run powerful AI on their own systems. This showed that being open didn’t reduce quality, it actually helped new ideas spread faster.
The Era of Efficiency
As we close 2025, Liang Wenfeng’s “crazy bet” has paid off in a way even he couldn’t have predicted. DeepSeek stands not just as a participant in the AI race, but as one of its primary frontrunners. While the world expected another incremental update, DeepSeek V3 delivered a knockout punch.
It didn’t just match standard models, as seen in the benchmarks below, DeepSeek-R1 went head-to-head with OpenAI’s most advanced reasoning model, o1, effectively tying or beating it on complex math and coding tasks (AIME, Codeforces).
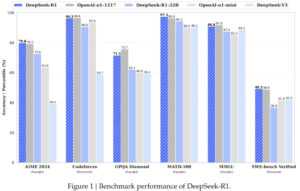
Source: https://api-docs.deepseek.com/news/news250528
The reports revealed that while the competitors spent an estimated $100+ million training their models, DeepSeek trained V3 for approximately $5.6 million. Today, with the recent release of DeepSeek V3.2, they are no longer the “underdog from Hangzhou”; they are now one of the “Big Four”. While the industry has shifted and the days of blindly scaling the parameters are over, the new metric for success is Inference Efficiency. It’s like how much intelligence can you squeeze out of every watt of electricity?
In the history of technology, there are those who build larger castles, and those who invent better bricks. DeepSeek did the latter. They proved that the future of AI isn’t about who owns the most supercomputers, but who writes the most efficient code. This revelation cost the hardware giants billions. They reminded the world that in computer science, constraints are not just obstacles, they are the motives of invention. By refusing to accept that “Intelligence” must equal “Expense”, they turned a luxury technology into a commodity, handing the source code of the future to every developer with a laptop.
know more about AI efficiency, architecture, and real-world optimization –>
-
Vibe Coding: How AI Is Transforming Software Development
https://codesmiths.in/vibe-coding-ai-software-development/ -
AlphaFold and Levinthal’s Paradox: How AI Solved an Impossible Biology Problem
https://codesmiths.in/alphafold-levinthals-paradox-ai/ -
Headless UI with React and Tailwind: Building Efficient Frontends
https://codesmiths.in/headless-ui-react-tailwind/


