

Deepfake Detection Architecture: How Modern Cybersecurity Verifies Trust in Synthetic Media
As deepfake technology has advanced from a research experiment into a serious security threat, organizations can no longer rely on traditional methods to verify digital content. AI-generated videos, images, and audio are now realistic enough to be used in fraud, impersonation, and large-scale deception. To counter this risk, deepfake detection architectures have become a critical part of modern cybersecurity defenses.
Introduction: Why Detection Matters Now
Deepfake technology has evolved from experimental novelty to a genuine security crisis. AI-generated videos, images, and audio have become sophisticated enough to deceive even trained observers, creating serious vulnerabilities across financial systems, corporate communications, and legal proceedings. The 2019 UK energy company incident, where attackers used AI-generated voice to steal $243,000, demonstrates that these threats are not hypothetical—they’re happening now.
Traditional security relied on a simple assumption: if you could see or hear someone, you could trust their identity. Deepfakes have shattered this assumption entirely. Every video conference, voice call, and piece of digital media now requires systematic verification through multiple independent channels. Organizations can no longer afford to trust digital content at face value.
Modern deepfake detection architectures respond to this challenge by combining multiple specialized techniques into layered defense systems. Rather than depending on a single detection method, these systems use diverse approaches that work together to identify synthetic media created by different AI models.
The Architecture Challenge
What makes detection so difficult?
Deepfake generation itself is powered by AI, which means detection systems are defending against adversarial models that continuously evolve to bypass safeguards. This creates an ongoing arms race where detection architectures must be adaptive and regularly updated rather than static security solutions.
Core detection approaches include:
- Video stream authentication
- Liveness detection systems
- Machine learning-based content analysis
- Behavioral and temporal consistency checks
Each layer focuses on different signals, making the overall system more resilient against sophisticated attacks.
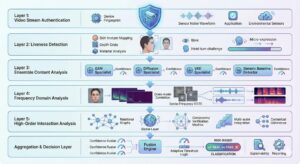
Layer 1: Foundational Layer – Liveness Detection and Video Stream Authentication
The Foundation of Trust
Before determining whether media is AI-generated, systems must first confirm they’re analyzing a real, live video stream from a physically present person. This protects against two primary attack types: presentation attacks (showing fake biometric material like photos or masks to a camera) and video injection attacks (bypassing the camera by feeding pre-recorded or AI-generated video directly into verification software).
Active vs. Passive Liveness Detection
Active liveness detection asks users to perform random actions—blink, smile, turn their head. While highly reliable when challenges are unpredictable, this approach adds friction and degrades user experience.
Passive liveness detection represents the modern approach. These systems verify authenticity without user interaction by analyzing skin texture, depth cues, light reflection patterns, and subtle involuntary facial movements. They can extract 3D information from a single image, making verification fast, user-friendly, and scalable. The challenge lies in continuous improvement to counter advanced masks and high-quality displays.
Video Stream Authentication
Liveness checks fail if attackers replace the camera feed itself. Stream authentication ensures input originates from a real physical camera through several techniques:
- Device fingerprinting to confirm genuine camera hardware
- Sensor noise analysis to detect patterns unique to physical image sensors
- Frame consistency checks to identify unnatural compression or timing
- Application integrity checks to detect tampering or virtualized environments
This layered approach forms the foundation for all higher-level deepfake detection techniques.
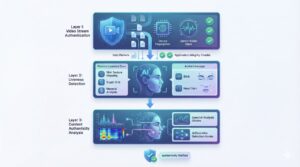
Layer 2: Ensemble Detection Architecture – The Team of Specialists
The Generalization Problem
Single deepfake detection models often perform well only on the types of synthetic media they were trained on. A detector trained primarily on GAN-generated content might achieve 95% accuracy on GAN-based deepfakes but fall to 60% accuracy when analyzing diffusion model outputs. This generalization failure creates critical security vulnerabilities as attackers adopt new generation techniques.
How Ensembles Solve This
Modern systems use ensemble architectures—multiple specialized detectors working together as a unified system. Think of it like a medical team where each doctor specializes in different conditions.
Key principles:
- Diversity over individual accuracy: Effectiveness depends more on detector diversity than peak performance
- Specialized detectors: Each model focuses on specific generation families (GAN specialist, diffusion specialist, VAE specialist, generic detector)
- Collective resilience: Combined detectors achieve near-specialist performance across multiple deepfake categories
Implementation Design
In ensemble systems, input media is analyzed simultaneously by all detectors. Each model independently produces a confidence score based on its expertise, and results are aggregated to determine the final classification.
A detector with moderate overall accuracy might excel at identifying specific edge cases that high-performing models miss. By maintaining diverse detector portfolios, ensemble architectures ensure that unusual cases don’t slip through primary detectors.
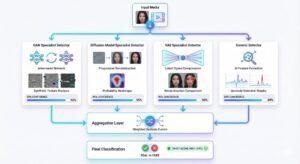
Layer 3: Frequency Domain Analysis – Beyond Human Perception
Beyond Human Perception
While humans look for visible signs of manipulation like unnatural facial expressions or lighting errors, advanced systems analyze media in ways humans cannot perceive. Frequency domain analysis examines the mathematical structure of images, video, and audio, revealing hidden patterns that strongly indicate synthetic generation—patterns that remain even when deepfakes appear visually flawless.
Spectral Analysis: Mathematical Signatures
Discrete Cosine Transform (DCT) analysis converts images from the spatial domain (pixels) into the frequency domain, showing how visual information is distributed across frequencies. Deepfake generation models, especially GANs, struggle to perfectly reproduce natural frequency distributions, leaving distinct spectral patterns.
The detection process:
- Convert images into frequency space using DCT
- Analyze frequency coefficient distributions
- Compare results against known authentic baselines
Even when images look realistic to human eyes, frequency artifacts often remain, making spectral analysis a powerful detection signal.
Temporal Frequency Analysis
Beyond individual frames, detection systems analyze how pixels change over time. Real video exhibits consistent temporal behavior influenced by physical camera sensors, video compression methods, and natural lighting. Deepfake videos introduce subtle temporal inconsistencies—frame-to-frame changes invisible to humans but mathematically detectable.
The process:
- Extract pixel-wise signals tracking how each pixel’s value changes across frames
- Apply frequency analysis to pixel time-series data
- Use region-based weighting to automatically focus on facial areas like the mouth and nose
These regions are harder to synthesize consistently and tend to reveal generation artifacts. Most importantly, temporal frequency artifacts remain relatively consistent across different deepfake generation methods, and these signals are completely invisible to human observers—a rare case where machines definitively outperform human judgment.
Layer 4: High-Order Interaction Analysis – Seeing the Forest Through Game Theory
Why Isolated Details Mislead
Focusing on small visual details—an unusual eye shape, distorted ears, imperfect skin texture—seems logical but often reduces detection accuracy. Modern deepfake models excel at generating locally realistic features. Individual facial components may look perfectly authentic when examined alone. The weaknesses of synthetic media appear not in individual features but in how those features relate to one another.
Understanding Interaction Levels
Low-order interactions examine features independently, without considering spatial or contextual relationships—analyzing small patches of eyes or mouths in isolation.
High-order interactions evaluate features within their full context: how facial elements align, how lighting behaves across the face, whether textures and proportions remain consistent throughout the scene.
Research demonstrates that low-order interactions often contribute negatively to detection accuracy, while high-order interactions provide the most reliable signals. Deepfake generation struggles with maintaining global consistency. Facial features may not align naturally, lighting may be inconsistent across regions, and subtle relationships between movement, texture, and geometry may break down.
Integrated Defense Systems
Real-Time vs. Forensic Detection
Detection architectures must support two distinct operational scenarios:
Real-Time Detection (live video calls, biometric authentication):
- Decisions within milliseconds or seconds
- Lightweight, fast detection methods
- Progressive analysis—quick initial checks followed by deeper inspection if risk detected
Forensic Detection (incident investigation, legal evidence review):
- Maximum accuracy required
- Apply all detection layers including computationally intensive techniques
- Generate detailed reports explaining classification decisions
Explainability and Human Oversight
As deepfake detection is increasingly used in regulated and legal environments, explainability is essential. Modern architectures provide attribution visualizations, layer-by-layer reporting with confidence scores, uncertainty estimates, and human-in-the-loop workflows allowing experts to review borderline cases. This transparency builds trust and ensures detection systems support informed human decision-making.
Conclusion: The Future of Detection Architecture
Modern deepfake detection has evolved far beyond simple artifact identification. The integration of liveness verification, ensemble learning, frequency domain analysis, and high-order interaction assessment creates multi-layered defense systems significantly more resilient than early approaches.
Current achievements include:
- Ensemble methods providing robust generalization across diverse generation techniques
- Defense-in-depth architectures addressing video injection attacks alongside content manipulation
However, this is an ongoing arms race. As generation techniques improve, detection systems must continuously adapt. Organizations must treat every digital interaction with systematic skepticism until verified through multiple independent channels. The assumption that seeing or hearing is believing no longer holds. In its place, we need architectures that verify trust through layered, diverse, and constantly evolving detection systems.
The future of digital security depends on maintaining this vigilance. Deepfake detection architecture isn’t just a technical solution—it’s a fundamental shift in how we establish trust in an era where synthetic media is indistinguishable from reality.
Know more about relevant topics:
How One Research Paper Crashed NVIDIA Overnight:
The Equation That Broke Isaac Newton:


